
二分查找是用于有序序列的高效查找算法,平均时间复杂度为 lg(n)。
有序序列可分为单调不减,例如 1, 2, 3, 3, 3, 5;以及单调不增序列,例如 5, 3, 3, 3, 2, 1。
也就是说,序列中可以出现重复的值,但是值的大小只能往一个方向变化。
序列中可能存在多个目标值,查找方[......]
二分查找是用于有序序列的高效查找算法,平均时间复杂度为 lg(n)。
有序序列可分为单调不减,例如 1, 2, 3, 3, 3, 5;以及单调不增序列,例如 5, 3, 3, 3, 2, 1。
也就是说,序列中可以出现重复的值,但是值的大小只能往一个方向变化。
序列中可能存在多个目标值,查找方[......]

如果我们想要在字符串“hello”中查找“he”,可以用暴力匹配、KMP、BM 算法等,但是如果想要同时查找“he”和“el“,又该如何实现?
最简单的方式就是先查找一遍”he“,然后再查找一遍”el“,如下图所示:
但这种方式的效率显然很低。为了更高效地完成多个模式串的匹配,贝[......]
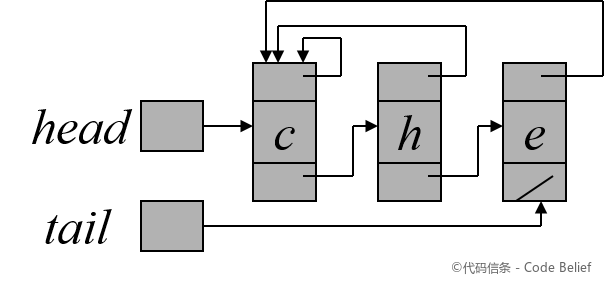
并查集是用于处理不相交集合的合并及查询问题,主要操作为:创建集合、合并两个不相交集合、判断两个元素是否属于同一个集合。
其中,判断两个元素是否属于同一个集合,可以这样考虑:为每个集合选一个代表元素,从而“判断两个元素是否属于同一个集合”就变成了“判断两个元素所在集合的代表元素是否相同”。
基本操[......]
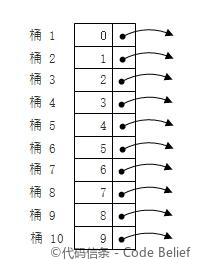
假设输入元素为:10,21,17,34,44,11,654,123,我们选择 10 作为基数进行基数排序。
首先,我们根据个位对元素进行分类:
0: 10
1: 21 11
2:
3: 123
4: 34 44 654
5:
6:
7: 17
8:
9:
依次收集元素,得到[......]
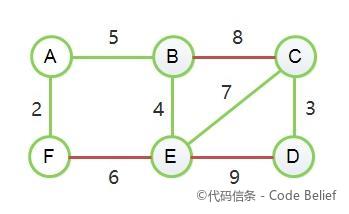
Prim 用于找出一个无向连通图的最小生成树(Minimum Spanning Tree)。首先初始化一个空集 S,然后选择一个起点,加入到 S 中。此后不断选择与 S 中的顶点距离最短的顶点,加入到 S 中,并输出这条最短的边。最终,所有点都将被加入到集合 S 中,而被输[......]

先序序列:ABDECF
中序序列:DBEAFC
步骤:

栈是计算机中非常基础而又极其重要的一种数据结构,许多算法的实现都离不开栈,它的特点是“先进后出”,也可以说“后进先出”。
打一个形象的比方:栈好比一个弹夹,最先放入的子弹只能最后打出;而最后放入的子弹则最先打出。
我们生活中接触的表达式大部分都是中缀[......]